How functional programming and type inference can help you to manage of large amounts of structured and unstructured data, merge multiple data sources and API, create visualizations for data interpretation, build mathematical models based on data, and present the data insights/findings?
Data science is an attempt to understand and interpret domain data using statistical analysis, machine learning, visualization and programming technologies and tools. The typical project starts with a shallow definition of the problem (e.g., forecast sales using store, promotion, and competitor data). The next stage is data collection, which includes data acquisition, consolidation and management. Collected data is analysed and modelling approaches proposed. Then a model or several models are built and evaluated using collected data. After the successful presentation and implementation in production the cycle repeats using new data, new models, etc.
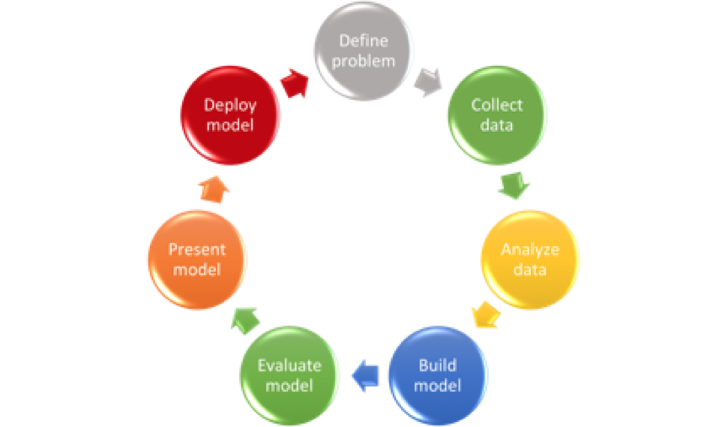
Thus, it is important to have tools that allow faster iterations, provide better visibility and produce production-ready models.
Which language/tool is more productive?
- The answer for statisticians is R because it has a huge number of packages and easy to use development environment.
- The answer for Web developers is probably Python because it has a significant number of packages for data analysis, which can be easily integrated with Web applications.
- The answer for Big Data developers is probably Clojure or Scala because they are tightly integrated with Java and can benefit from computing power of Hadoop, Scalding and Spark.
Would anyone choose F# for data science?
F# was created in Microsoft Research, Cambridge and it was not the first functional language for the .Net platform, but the first that have chosen functional-first programming paradigm. There are many advantageous features offered by the F# language for data science:
- Functional Programming - functions as first-class objects, clojures and higher-order functions are natural ways to express many data mining tasks
- Strong Static Syping - strong typing-time type checking by IDE and compile-time checking by compiler detect many errors at early stages that is extremely important for machine learning algorithms with days and weeks of execution
- Type Inference - automatic inference of the types of values dramatically reduces typing efforts and source code size while improving readability
- Generics - automatic generalization of functions and generalized data structures greatly simplify the writing of reusable and high-performance code
- Interoperability - F# functions can call and be called from other .Net languages and easily call native code libraries
However, there three important questions that need to be answered:
- Do features of F# help to develop fast and effective algoritms?
- Does F# have packages that can help in development?
- Are F# and Mono platform mature enough to run on hundreds servers?